












2025年02月12日
经过昇思MindSpore开源社区开发者们几个月的开发与贡献,现正式发布昇思MindSpore2.5版本。
其中动态图补齐view和in-place功能并优化动态shape能力,提升动态图执行性能;通过完善图算融合,增强静态图O1模式的泛化可用性;新增支持不占资源的仿真模拟集群执行流程,提高调优效率,同时Atlas A2上的已有功能平滑迁移到超节点,并发挥互联优势,甜点场景性能可达2.9x Atlas A2,不断提升框架易用性。
在大模型推理方面,金箍棒提供低比特权重量化和动态量化算法降低推理成本,并结合图算融合优化技术,降低推理整网时延提升吞吐量,同时支持DiT文生图模型以存代算及Gate算法降低端到端时延,实现大模型推理性能提升。
在工具效率提升方面,msprobe工具新增分级可视化构图比对,实现快速分析精度问题,同时Profiler实现轻量化打点,支持集群场景问题快速定界。
下面就为大家详细解读昇思2.5版本的关键特性。
——框架易用性提升——
1 动态图补齐view和in-place功能,提升Tensor索引性能平均3.4倍
在AI框架中,对Tensor(张量)的操作在普通计算类操作的基础上,存在两种特殊的操作:view(视图)操作 和 in-place(原地)操作。view操作是指创建一个新的张量,它与原始张量共享相同的数据存储,但具有不同的形状或排列方式,换句话说view操作不会复制数据,而是通过不同的视角来解释现有的数据,这使得view操作非常高效,因为它们避免了不必要的内存分配和数据复制;in-place操作是指直接修改输入张量的内容,而不创建新的张量,这种操作通常会在函数名后加上下划线_来表示它是in-place操作,例如,add_()是add()的in-place版本。
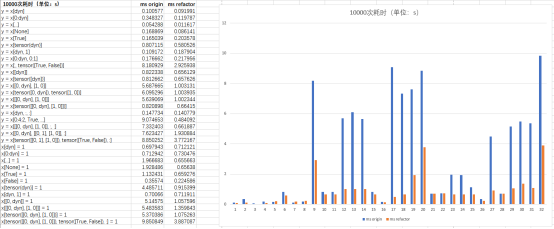
Tensor的索引操作是建立在view和in-place操作之上的一个复杂操作,昇思MindSpore 2.5版本动态图已经补齐view操作和in-place操作能力,提升了Tensor的索引操作的性能,如下图所示,不同场景下Tensor索引性能平均提升3.4倍。
2 反向完善动态shape能力,提升动态图执行性能30%
昇思MindSpore动态图在动态shape场景下,反向执行先构建完整的IR图,进而拆分成单算子进行执行,该流程下需要先构建整图再进行拆分,存在冗余的操作。针对该场景,昇思MindSpore2.5版本反向执行流程优化成建立逻辑连接关系,直接通过连接关系进行执行,从而优化冗余操作,提升动态shape场景下动态图执行性能,SDXL网络和OpenSora网络端到端提升30%。
3 完善图算融合,增强静态图O1模式的泛化可用性
昇思MindSpore2.3版本首次对外发布支持静态图O(n)多级编译,其中O1模式主要是在O0基础上增加了图算融合优化支持,用于对训练性能要求更高的模型场景。
经过持续优化完善以及大范围测试验证,昇思MindSpore2.5版本中O1模式在泛化可用性上已经可以满足大部分场景需求。基于Atlas A2进行典型网络测试,如下图所示,使能O1模式可实现平均约10%的整网性能加速效果,具体收益跟网络结构、算子使用、张量Shape等相关。
当O1模式使能之后,图算融合可以在静态图编译过程中自动识别可融合子图并进行融合替换。相比手工融合,图算融合具有简单易用、泛化性好等优势。
参考链接:https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore/mindspore.JitConfig.html
4 超节点功能平滑迁移,全面发挥互联优势
昇思MindSpore在Atlas A2上的已有功能无需修改即可平滑迁移到Atlas A3,充分发挥Atlas A3的硬件能力,全面支持模型的训练和推理流程。在超节点甜点场景上,昇思MindSpore使能高维张量并行、RingAttention等亲和特性,其中高维张量并行在通信节省基础上进一步实现超节点硬件亲和的Matmul计算shape切分策略优化、充分释放超节点硬件性能,支持千亿稠密Llama模型性能提升10%~20%。充分发挥互联优势,典型千亿稀疏模型长序列性能Atlas A3可达2.9x Atlas A2,支持M级tokens的序列长度训练。
5 新增支持不占资源的仿真模拟集群执行流程,提高调优效率
通常在训练时为了提升设备的算力或显存利用率,往往需要反复调试并行策略、重计算、负载均衡等相关超参,对于动辄千卡万卡的大集群来说,这种反复调试成本是非常昂贵的。而昇思MindSpore2.5版本新增支持仿真模拟执行的功能,可以在不占用卡执行的情况下,直接模拟出任意卡的图编译结果以及显存占用情况,如下图所示,用户可以根据模拟执行的显存结果来调整上述超参,调整完后再复用到生产集群上,一键拉起大集群训练,从而减少调试过程中的资源占用,大幅提升调试调优效率。

用户可以根据自己的需求,通过环境变量export MS_SIMULATION_LEVEL=0/1/2/3设置模拟执行的级别。0代表仅模型编译,用户可以关注模型编译时间;1在0的基础上记录了算子的输入、输出显存信息,用户可以结合显存统计或者memory_tracker进行显存分析;2在1的基础上增加了算子workspace显存信息,需要占用期望模拟的卡数;3在2的基础上增加了当前卡的计算算子执行过程,用户可以进行性能调优。
——大模型推理性能提升——
6 金箍棒支持低比特权重量化和动态量化算法,降低推理成本
6.1 金箍棒新增AWQ和GPTQ算法,并提供4bit权重量化推理能力,缩减40%推理时延和60%参数量
AWQ(Activation-Aware Weight Quantization)是一种低比特权重量化算法,基于激活值分布挑选显著权重,并且考虑到硬件效率,通过缩放的方式来保护显著权重,实现了硬件友好的高精度权重量化算法;与AWQ算法功能相似,GPTQ(Gradient-based Post-training Quantization)算法也是一种低比特权重量化算法,其核心思想是对某个block内的所有参数逐个量化,每个参数量化后,需要适当调整这个block内其他未量化的参数,以弥补量化造成的精度损失。
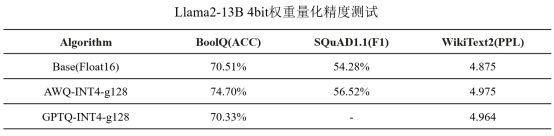
在昇思MindSpore2.5版本中,金箍棒复现了这两个权重量化算法,并优化了4bit权重量化的推理性能。我们在昇腾Atlas 800I A2硬件上使用8卡Tensor并行推理进行性能和精度测试,结果如下表所示,AWQ和GPTQ在BoolQ,SQuAD1.1和WikiText2数据集上实现了精度几乎无损的A16W4量化。
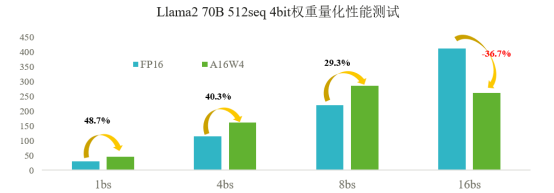
针对Llama2 70B网络,如下图所示,4bit权重量化在batch_size小于8的情况下最多可以获得48.7%的时延收益;但当batch_size大于等于16时,受限于昇腾硬件架构,4ibt权重量化在时延上会产生负收益。
参考链接:https://gitee.com/mindspore/golden-stick/tree/master/mindspore_gs/ptq/ptq#gptq%E7%AE%97%E6%B3%95
6.2 金箍棒新增激活动态量化算法,提升8bit量化的精度
一些对精度十分敏感的模型和任务,即使通过SmoothQuant等异常值抑制技术仍然难以满足精度要求,此时可以通过牺牲一些8bit量化的性能收益,通过动态量化来进一步降低量化的精度损失。
与权重量化不同,在离线量化阶段算法不能获取真实的激活值,只能通过校准集近似统计激活的分布,这会带来额外的量化饱和误差。激活动态量化是指在推理过程中实时统计激活的分布来进行量化推理,实现更小的量化精度损失。
在昇思MindSpore2.5版本中,金箍棒提供了激活动态量化算法,结合权重静态量化和SmoothQuant异常值抑制技术,可以提供精度几乎无损的8bit量化能力。我们在昇腾Atlas 800I A2硬件上使用8卡Tensor并行进行测试,结果如下表所示,激活动态量化算法在C-Eval和SQuAD1.1数据集上实现精度无损的A8W8量化。

我们针对RMSNorm和DynamicQuant算子做了融合优化,在Llama2 57B网络,如下图所示,输入batch_size范围[1, 16],seq_length范围[512, 2048],获得端到端耗时缩减3.8%~8.1%。
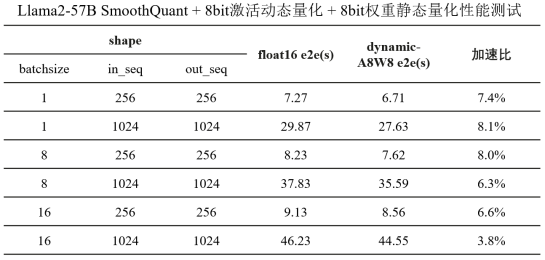
7 结合图算融合优化技术,降低推理整网时延,提升吞吐量
昇思MindSpore2.5版本使用图算融合技术针对性处理多类量化场景,减少额外量化操作带来的下发耗时和内存访问,并通过昇腾亲和的融合算子实现提升计算效率,与量化压缩、PrefillFlatten技术协同,配合Atlas A2及Atals推理系列产品达成降低整网时延、提升吞吐的优化效果。
7.1 融合隐藏量化计算开销,整网加速3-8%
PagedAttention支持使用量化的KVCache作为输入,并在算子内融合反量化操作,利用昇腾硬件Cube/Vector特性实现多计算流水并行,使Cube/Vector计算时延互相掩盖,明显提升算子运行性能,相较浮点输入性能提升10%以上。
同时我们提供以RmsNorm为主体的融合pattern,将前向Add和后向量化计算融合成更大的Vector算子,利用多路融合并行、UB Bank冲突优化、Inplace内存复用等关键技术,融合前后算子性能提升10-30%。上述融合同时支持Quant算子(Per Channel量化)和DynamicQuant算子(Per Token激活动态量化)。
另外,此前版本已支持的MatMul并行融合及后向融合,在昇思MindSpore2.5版本中亦支持了量化数据类型的输入。
7.2 PrefillFlatten负载均衡,吞吐量提升5%
大模型推理场景处理序列数据时,通常会使用填充(padding)来使序列长度一致以便于批处理,无法避免地会增加冗余计算量。
昇思MindSpore2.5版本通过PrefillFlatten方法,将输入序列以真实长度进行拼接,无需填充到统一长度;针对这一优化,Attentoin计算模块(FlashAttention、PagedAttention、ApplyRotaryPosEmb算子)结合昇腾芯片特性,在算子内对输入序列真实长度进行排序,根据每个 Batch 的计算量动态分配不同的核数,确保较长的序列可以分摊到不同计算单元上,可在减少计算量的同时确保每个计算单元的负载均衡,同时优化Vector计算流水并行任务,提升UB利用率,进一步提高整体计算效率10%以上。
7.3 FlexFormat融合实现矩阵乘优化,整网加速5-7%
Atlas推理硬件上Cube计算所需特殊Format与原生Format间的频繁转换会引入大量开销,且同一算子使用不同Format实现的性能亦有较大差异。针对此问题,昇思MindSpore2.5版本实现了更为灵活的Format选择及算子融合优化方案,结合高效的UB调度、Buffer复用等技术,使Cube计算可基本掩盖Format转换耗时,从而大幅提升性能。该方案优化支持浮点类型、量化类型及稀疏量化等多类MatMul算子,单算子融合前后性能提升3-40%,端到端性能提升5-7%。
8 支持DiT文生图模型以存代算及Gate算法,降低端到端时延32%
8.1 以存代算算法降低注意力机制计算量,端到端加速24%
主流的文本生成图像模型采用了基于注意力机制的多步迭代扩散去噪方法。在多步迭代过程中,相邻的时间步骤间通常存在冗余计算,这些计算具有高度相似性。通过识别和复用这些冗余计算的结果,可以在保持精度的同时减少计算量。
基于该思想并借鉴Delta-Cache的设计理念,昇思MindSpore 2.5版本引入了针对DiT文生图模型的以存代算(Cache)算法。如下图所示,该方法对前一个时间步(xt)中特定两个位置特征值(⑦-⑥)的偏移量进行缓存,并在下一个时间步(xt-1)中将这个偏移量直接应用到B1层的输入上,从而跳过了从B1到B3的计算过程。
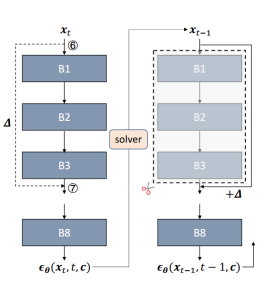
不同于Delta-Cache所采用的部署策略,我们对参数进行了重新调整,以更好地适应不同的模型结构。在SD3模型上的测试结果显示,当生成分辨率为1024*1024像素的图片时,该算法能够在精度几乎无损的前提下减少约24%的端到端推理延迟。
8.2 叠加Gate算法,推理额外加速10%
主流的文生图模型大多采用了无分类器引导(Classifier-Free Guidance, CFG)技术,其特点是在每次迭代过程中执行两次生成过程:一次是无条件引导,另一次是有条件的文本引导。实验发现,在迭代后期专注于提升图像质量的过程中,无条件引导对生成结果的影响相对较小。
基于这一观察,昇思MindSpore 2.5版本引入了Gate算法,允许在采用CFG技术的文本生成图像模型中,在特定的时间步停用无条件引导计算。此外,Gate算法可以与前述的以存代算(Cache)算法协同使用,进一步优化性能。在SD3模型上应用Gate算法后,相较于仅使用以存代算(Cache)算法的情况,推理时延降低了额外的10%,达成总计约32%的推理加速。
参考链接:https://github.com/mindspore-lab/mindone/tree/master/examples/dit_infer_acceleration
——工具效率提升——
9 msprobe工具新增分级可视化构图比对,实现快速分析精度问题
针对大模型场景精度问题定位效率低,精度数据呈现不直观的问题,msprobe工具新增支持昇思MindSpore场景分级可视化构图比对,实现模型各个层级的精度数据比对,方便用户理解模型结构,快速分析精度问题。如下图所示,用户可以选择单图构建查看模型结构,也可以选择双图比对,实现昇思MindSpore与PyTorch的跨框架比对。可视化构图比对展示了模型的层级结构,并且每个节点都展示了输入输出数据信息、堆栈信息等,支持按节点名称搜索和按节点颜色进行精度筛选。
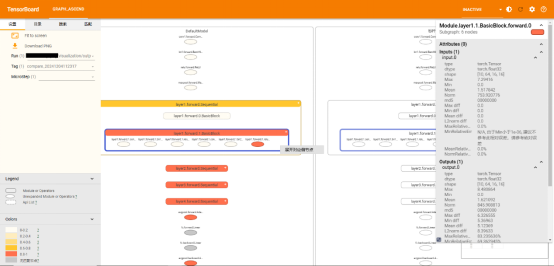
msprobe工具支持基于模型结构的精度可视化对齐和分析,一键找到模型实现差异、精度异常节点,大大提升精度对比分析效率。
10 Profiler实现轻量化打点,支持集群场景问题快速定界
针对大集群场景传统Profiler流程重、数据量大的问题,昇思MindSpore2.5版本提供轻量化Profiler能力,帮助大集群场景轻量化获取模型关键指标性能数据。如下图所示,用户可通过mstx.mark、mstx.range_start、mstx.range_end接口自定义打点,同时支持通信算子的内置打点,用户开启轻量化打点功能,通讯算子前后将自动实现打点。所有的打点任务由runtime下发至device侧,可呈现打点任务在host侧和device侧的时间点或时间片。
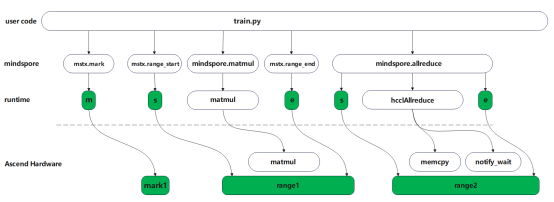
轻量化打点可支撑昇思MindSpore2.5大集群训练业务场景,提供大集群场景少量数据即可定位问题边界能力。
相关导航






